


Suivre l’évolution d’une industrie aussi rapide que IA est un défi de taille. En attendant qu’une IA puisse le faire à votre place, voici un tour d’horizon pratique des histoires récentes dans le monde de l’apprentissage automatique, ainsi que des recherches et des expériences notables que nous n’avons pas couvertes seules.
Cette semaine, dans le domaine de l’IA, j’aimerais braquer les projecteurs sur les startups d’étiquetage et d’annotation – des startups comme Scale AI, qui est aurait en pourparlers pour lever de nouveaux fonds pour une valorisation de 13 milliards de dollars. Les plates-formes d’étiquetage et d’annotation pourraient ne pas attirer l’attention sur les nouveaux modèles d’IA générative comme le font Sora d’OpenAI. Mais ils sont essentiels. Sans eux, les modèles d’IA modernes n’existeraient sans doute pas.
Les données sur lesquelles de nombreux modèles s’entraînent doivent être étiquetées. Pourquoi? Les étiquettes, ou balises, aident les modèles à comprendre et à interpréter les données pendant le processus de formation. Par exemple, les étiquettes destinées à entraîner un modèle de reconnaissance d’images pourraient prendre la forme de marquages autour des objets.boîtes englobantes» ou des légendes faisant référence à chaque personne, lieu ou objet représenté dans une image.
La précision et la qualité des étiquettes ont un impact significatif sur les performances (et la fiabilité) des modèles formés. Et l’annotation est une vaste entreprise, nécessitant des milliers, voire des millions d’étiquettes pour les ensembles de données les plus volumineux et les plus sophistiqués utilisés.
On pourrait donc penser que les annotateurs de données seraient bien traités, payés un salaire décent et bénéficieraient des mêmes avantages dont bénéficient les ingénieurs qui construisent eux-mêmes les modèles. Mais souvent, c’est le contraire qui est vrai – en raison des conditions de travail brutales favorisées par de nombreuses startups d’annotation et d’étiquetage.
Les entreprises possédant des milliards en banque, comme OpenAI, se sont appuyées sur les annotateurs des pays du tiers monde ne payaient que quelques dollars de l’heure. Certains de ces annotateurs sont exposés à des contenus très dérangeants, comme des images graphiques, mais ne bénéficient pas de congés (car ce sont généralement des sous-traitants) ni d’accès à des ressources en santé mentale.
Un excellent morceau dans NY Mag lève notamment le voile sur Scale AI, qui recrute des annotateurs dans des pays aussi lointains que Nairobi ou le Kenya. Certaines des tâches de Scale AI nécessitent aux étiqueteurs plusieurs journées de travail de huit heures – sans pause – et ne paient que 10 $. Et ces travailleurs sont soumis aux caprices de la plateforme. Les annotateurs passent parfois de longues périodes sans recevoir de travail, ou sont expulsés sans ménagement de Scale AI – comme cela est arrivé aux entrepreneurs en Thaïlande, au Vietnam, en Pologne et au Pakistan. récemment.
Certaines plateformes d’annotation et d’étiquetage prétendent proposer un travail de « commerce équitable ». En fait, ils en ont fait un élément central de leur image de marque. Mais comme Kate Kaye du MIT Tech Review Remarquesil n’y a pas de réglementation, seulement des normes industrielles faibles sur ce que signifie le travail d’étiquetage éthique – et les définitions des entreprises varient considérablement.
Alors que faire? À moins d’une avancée technologique massive, la nécessité d’annoter et d’étiqueter les données pour la formation en IA ne disparaîtra pas. Nous pouvons espérer que les plateformes s’autorégulent, mais la solution la plus réaliste semble être l’élaboration de politiques. C’est en soi une perspective délicate – mais c’est la meilleure chance que nous ayons, je dirais, pour changer les choses pour le mieux. Ou du moins, je commence à le faire.
Voici quelques autres histoires intéressantes sur l’IA de ces derniers jours :
-
- OpenAI construit un cloneur de voix : OpenAI présente en avant-première un nouvel outil basé sur l’IA qu’il a développé, Voice Engine, qui permet aux utilisateurs de cloner une voix à partir d’un enregistrement de 15 secondes d’une personne parlant. Mais l’entreprise choisit de ne pas (encore) le diffuser largement, invoquant des risques d’utilisation abusive et abusive.
- Amazon double sa mise sur Anthropic : Amazon a investi 2,75 milliards de dollars supplémentaires dans la puissance croissante de l’IA d’Anthropic, dans le prolongement de l’option qu’il a laissée ouverte en septembre dernier.
- Google.org lance un accélérateur : Google.org, l’aile caritative de Google, lance un nouveau programme de 20 millions de dollars sur six mois pour aider à financer des organisations à but non lucratif développant des technologies qui exploitent l’IA générative.
- Une nouvelle architecture de modèle : La startup d’IA AI21 Labs a publié un modèle d’IA génératif, Jamba, qui utilise une nouvelle architecture de modèle (ish) – les modèles d’espace d’état, ou SSM – pour améliorer l’efficacité.
- Databricks lance DBRX : Dans d’autres actualités sur les modèles, Databricks a publié cette semaine DBRX, un modèle d’IA générative semblable à la série GPT d’OpenAI et à Gemini de Google. La société affirme avoir obtenu des résultats de pointe sur un certain nombre de tests d’IA populaires, y compris plusieurs raisonnements de mesure.
- Uber Eats et la réglementation britannique sur l’IA: Natasha écrit sur la façon dont la lutte d’un coursier Uber Eats contre les préjugés liés à l’IA montre que la justice dans le cadre de la réglementation britannique sur l’IA est durement gagnée.
- Orientations de l’UE en matière de sécurité électorale : L’Union européenne a publié mardi un projet de lignes directrices sur la sécurité des élections destinées aux populations environnantes. deux douzaines plateformes réglementées par le Loi sur les services numériques, y compris des lignes directrices visant à empêcher les algorithmes de recommandation de contenu de diffuser une désinformation générative basée sur l’IA (alias deepfakes politiques).
- Grok est mis à niveau : Le chatbot Grok de X bénéficiera bientôt d’un modèle sous-jacent amélioré, Grok-1.5 — en même temps, tous les abonnés Premium sur X le recevront. accéder à Grok. (Grok était auparavant exclusif aux clients X Premium+.)
- Adobe étend Firefly : Cette semaine, Adobe a dévoilé les services Firefly, un ensemble de plus de 20 nouvelles API, outils et services génératifs et créatifs. Adobe a également lancé des modèles personnalisés, qui permettent aux entreprises d’affiner les modèles Firefly en fonction de leurs actifs. GenStudio suite.
Plus d’apprentissages automatiques
Quel temps fait-il? L’IA est de plus en plus capable de vous le dire. J’ai noté quelques efforts dans prévisions horaires, hebdomadaires et centenaires il y a quelques mois, mais comme pour tout ce qui concerne l’IA, le domaine évolue rapidement. Les équipes derrière MetNet-3 et GraphCast ont publié un article décrivant un nouveau système appelé GRAINESpour Échantillonneur de diffusion d’enveloppe d’ensemble évolutif.
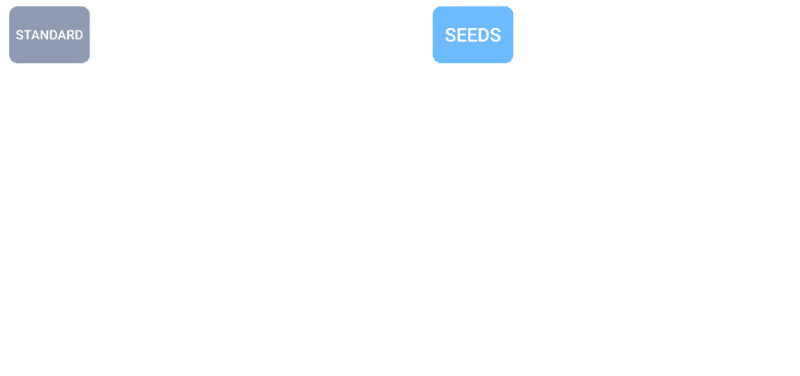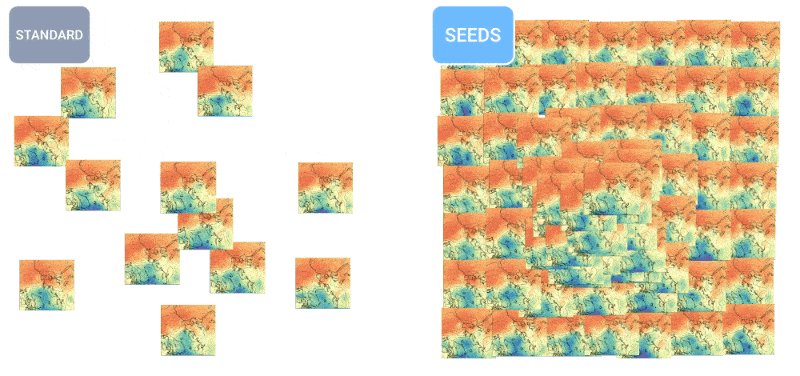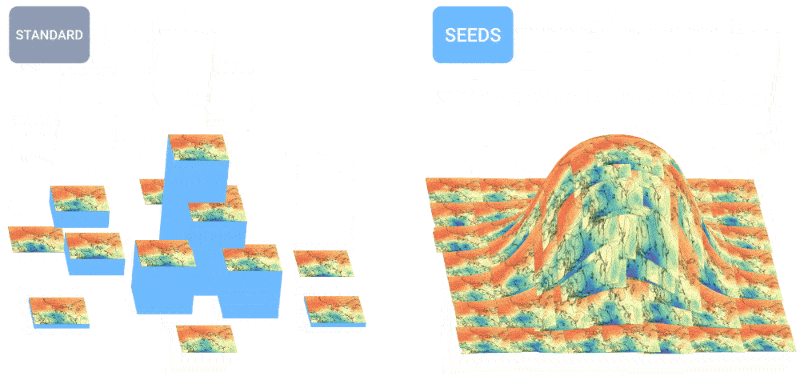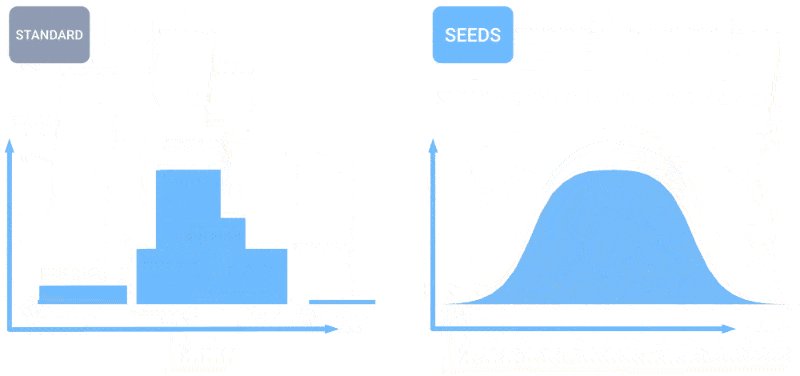
Animation montrant comment un plus grand nombre de prévisions crée une répartition plus uniforme des prévisions météorologiques.
SEEDS utilise la diffusion pour générer des « ensembles » de résultats météorologiques plausibles pour une zone en fonction des données d’entrée (lectures radar ou imagerie orbitale peut-être) beaucoup plus rapidement que les modèles basés sur la physique. Avec un plus grand nombre d’ensembles, ils peuvent couvrir davantage de cas extrêmes (comme un événement qui ne se produit que dans 1 scénario possible sur 100) et être plus confiants quant aux situations les plus probables.
Fujitsu espère également mieux comprendre le monde naturel en appliquer des techniques de traitement d’images IA à l’imagerie sous-marine et les données lidar collectées par des véhicules autonomes sous-marins. L’amélioration de la qualité de l’imagerie permettra à d’autres processus moins sophistiqués (comme la conversion 3D) de mieux fonctionner sur les données cibles.
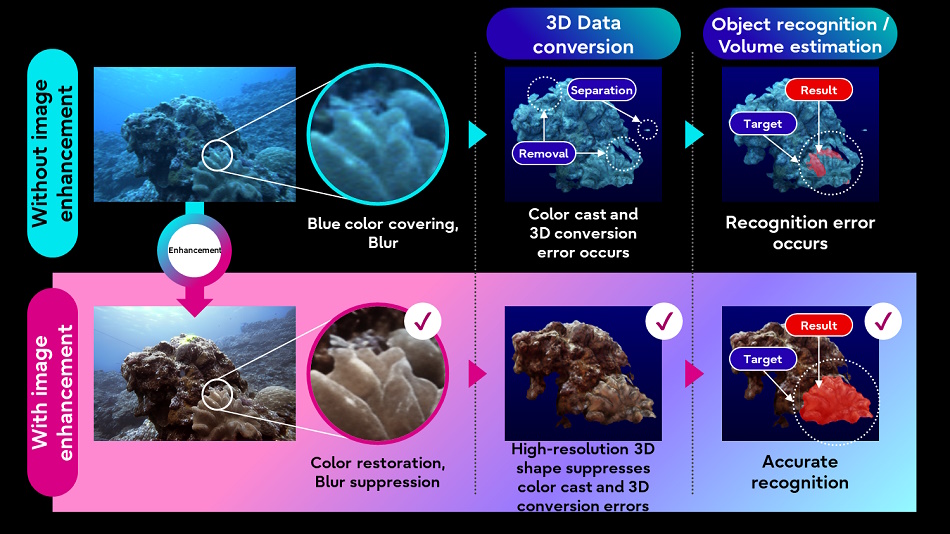
Crédits images : Fujitsu
L’idée est de construire un « jumeau numérique » des eaux qui puisse aider à simuler et à prédire de nouveaux développements. Nous en sommes loin, mais il faut bien commencer quelque part.
Parmi les LLM, les chercheurs ont découvert qu’ils imitent l’intelligence par une méthode encore plus simple que prévu : les fonctions linéaires. Franchement, les mathématiques me dépassent (trucs vectoriels dans de nombreuses dimensions) mais cet article au MIT montre clairement que le mécanisme de rappel de ces modèles est assez… basique.
Même si ces modèles sont des fonctions non linéaires très complexes, entraînées sur de nombreuses données et très difficiles à comprendre, ils contiennent parfois des mécanismes très simples. Ceci en est un exemple », a déclaré le co-auteur principal Evan Hernandez. Si vous avez un esprit plus technique, consultez le journal ici.
L’une des raisons pour lesquelles ces modèles peuvent échouer est de ne pas comprendre le contexte ou les commentaires. Même un LLM vraiment compétent pourrait ne pas « comprendre » si vous lui dites que votre nom est prononcé d’une certaine manière, car il ne sait ou ne comprend rien. Dans les cas où cela pourrait être important, comme les interactions homme-robot, cela pourrait décourager les gens si le robot agissait de cette façon.
Disney Research étudie depuis longtemps les interactions automatisées entre les personnages, et ce nom prononciation et réutilisation du papier je viens d’arriver il y a peu de temps. Cela semble évident, mais extraire les phonèmes lorsque quelqu’un se présente et les coder plutôt que simplement le nom écrit est une approche intelligente.

Crédits images : Recherche Disney
Enfin, à mesure que l’IA et la recherche se chevauchent de plus en plus, il vaut la peine de réévaluer la manière dont ces outils sont utilisés et si cette union contre nature présente de nouveaux risques. Safiya Umoja Noble est une voix importante dans le domaine de l’IA et de l’éthique de la recherche depuis des années, et son opinion est toujours éclairante. Elle a fait une belle interview avec l’équipe de presse de l’UCLA sur la façon dont son travail a évolué et pourquoi nous devons rester froids face aux préjugés et aux mauvaises habitudes en matière de recherche.